Monitorowanie dostępności serwera polega na regularnym sprawdzaniu, czy wszystkie kluczowe usługi – takie jak strona internetowa, baza danych, poczta czy dostęp sieciowy – działają prawidłowo i są dostępne dla użytkowników. W najprostszym wariancie monitoring sprowadza się do sprawdzania, czy strona odpowiada na zapytania użytkowników, ale skuteczna kontrola dostępności obejmuje również inne warstwy infrastruktury serwerowej.
Dlaczego to takie ważne? System monitoringu umożliwia bieżącą kontrolę działania stron internetowych i usług online. Niedostępność strony to potencjalna strata finansowa, pogorszenie pozycji w Google i utrata zaufania klientów. Monitoring uptime pozwoli Ci szybko wykrywać awarie, kontrolować działanie usług i zminimalizować ryzyko przestojów.
W tym artykule dowiesz się, jak działa monitoring dostępności, jakie narzędzia warto stosować i jak zbudować system alertów, który zareaguje, zanim użytkownik w ogóle zauważy usterkę. Jeśli prowadzisz firmę online, chcesz zadbać o SEO czy uniknąć utraty klientów – ten przewodnik przygotowaliśmy z myślą o osobach, które same zarządzają stronami, serwerami lub usługami online – i chcą mieć realną kontrolę nad ich dostępnością, niezależnie od wielkości projektu.

Podstawy monitorowania dostępności serwera
W praktyce monitorowanie dostępności sprowadza się do regularnych testów, które weryfikują, czy serwer i powiązane z nim usługi działają zgodnie z oczekiwaniami. Najprostsze narzędzia sprawdzają jedynie, czy serwer odpowiada – zazwyczaj na pingi lub proste zapytania HTTP, takie jak próba otwarcia strony głównej (GET /), w odpowiedzi na które serwer powinien zwrócić kod 200, czyli informację, że wszystko działa poprawnie. Bardziej zaawansowane rozwiązania kontrolują także działanie poczty, baz danych, serwerów DNS, a nawet czas odpowiedzi i wydajność całej infrastruktury. To właśnie te elementy składają się na skuteczny monitoring uptime – pozwalający nie tylko wykrywać awarie, ale także zapobiegać im, zanim dotkną użytkownika końcowego.
Współczesne systemy monitorujące umożliwiają testy nawet co 5 sekund, jednak w praktyce wiele profesjonalnych narzędzi – takich jak UptimeRobot, StatusCake czy Better Stack – domyślnie stosuje interwał 30-sekundowy. To rozsądny kompromis między szybkością reakcji a obciążeniem serwera i ryzykiem fałszywych alarmów. Im szybciej wykryjesz awarię, tym większa szansa, że przywrócisz działanie serwisu, zanim klienci zdążą zrezygnować z zakupu, wysłać zgłoszenie do konkurencji czy opublikować negatywny komentarz.
Niezależnie od tego, czy korzystasz z hostingu współdzielonego, VPS-a czy własnego serwera, warto uruchomić niezależny monitoring z zewnętrznych lokalizacji. Dzięki temu zyskasz własne źródło informacji o dostępności usług.
Jak mierzy się uptime serwera
Uptime serwera to procent czasu pracy, w którym usługa jest dostępna dla użytkowników. Większość profesjonalnych dostawców hostingu deklaruje uptime przekraczający 99%. Jeśli szukasz hostingu, zwróć uwagę na gwarancje dostępności. Pozornie niewielkie różnice mają ogromny wpływ na rzeczywisty czas działania:
- 99% uptime – to nawet 3 dni i 15 godzin i 39 minut przestojów w skali roku;
- 99,9% uptime – to 8 godzin i 46 minut przestojów rocznie;
- 99,95% uptime – to zaś 4 godziny i 23 minuty rocznie.
Choć różnica między 99% a 99,9% może wydawać się niewielka, w praktyce oznacza nawet około 10-krotnie krótszy czas przestojów.
Rodzaje monitorowania dostępności
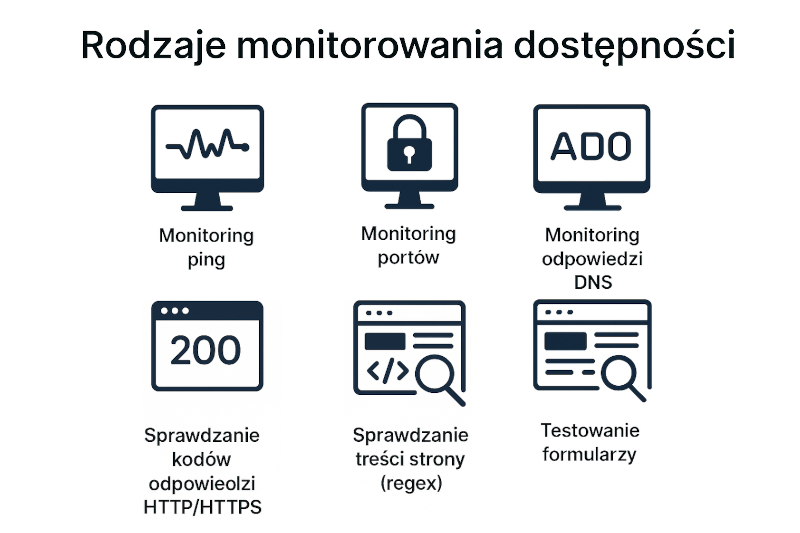
Istnieje kilka podstawowych rodzajów monitorów dostępności, które działają na różnych poziomach — od warstwy sieciowej po aplikacyjną — i pozwalają wykrywać problemy w różnych obszarach działania strony. Należą do nich:
- Monitoring ping – podstawowe testowanie połączenia sieciowego z serwerem poprzez wysyłanie krótkiego sygnału testowego. Pozwala wykryć problemy z siecią.
- Monitoring portów – kontrola działania konkretnych usług działających na serwerze (np. bazy danych, poczty elektronicznej).
- Monitoring odpowiedzi DNS – polega na sprawdzaniu, czy rekordy DNS domeny (np. A, AAAA, CNAME) są poprawnie skonfigurowane i czy serwery DNS odpowiadają prawidłowo. Umożliwia wykrycie błędów w konfiguracji domeny, opóźnień propagacji lub niedostępności serwerów DNS.
- Sprawdzanie kodów odpowiedzi HTTP/HTTPS (200) – to jedna z podstawowych metod weryfikacji dostępności strony na poziomie warstwy aplikacyjnej. Polega na wysyłaniu zapytań HTTP(S) do serwera i analizie otrzymywanych odpowiedzi. Oczekiwanym rezultatem jest kod 200, który oznacza, że serwer poprawnie przetworzył żądanie i odesłał odpowiedź. Potwierdza on jedynie poprawność odpowiedzi HTTP — nie daje gwarancji, że strona działa prawidłowo pod względem treści, wyglądu czy działania funkcji.
- Sprawdzanie treści strony (regex) – to weryfikacja, czy w treści odpowiedzi znajduje się określony element, ciąg znaków lub fragment kodu HTML. Pozwala potwierdzić, że strona nie jest pusta oraz że załadowała się poprawna treść (np. tytuł, przycisk, nagłówek).
- Testowanie formularzy – weryfikacja funkcjonalności elementów interaktywnych strony, takich jak formularze kontaktowe czy systemy logowania.
Wpływ niedostępności witryny na biznes
Każda minuta niedostępności witryny może oznaczać realne straty finansowe. W przypadku wystąpienia problemów z dostępnością tracisz nie tylko potencjalnych klientów, ale również zaufanie istniejących użytkowników. Badania z 2025 roku pokazują, że aż 88% użytkowników nie powraca na stronę, która była niedostępna podczas ich pierwszej wizyty.
W branży e-commerce czy usługach cyfrowych przestoje mogą wiązać się z utratą przychodów, szczególnie podczas kampanii promocyjnych czy w godzinach szczytu. W sektorach takich jak finanse, medycyna czy IT dostępność ma dodatkowe znaczenie związane z bezpieczeństwem danych oraz ciągłością procesów biznesowych.
Znaczenie wysokiego uptime dla pozycjonowania w Google
Wysoki uptime serwera wpływa na techniczną jakość strony, a tym samym na jej widoczność w Google. Podczas crawlowania (czyli automatycznego odwiedzania strony przez roboty Google) analizowany jest m.in. czas odpowiedzi serwera oraz jego dostępność. Problemy z dostępem – szczególnie jeśli występują w czasie indeksowania – mogą prowadzić do błędów i pogorszenia widoczności witryny.
Eksperci Google, w tym John Mueller (rzecznik techniczny Google, zajmujący się tematami SEO), podkreślają, że jednorazowy przestój trwający do 24–48 godzin zwykle nie wpływa negatywnie na SEO, ponieważ Googlebot sam podejmuje kolejne próby dostępu do strony. W takich przypadkach nie ma ryzyka spadku pozycji ani deindeksacji — pod warunkiem, że problem szybko zostanie rozwiązany.
Jeśli jednak przestoje trwają dłużej niż 2 dni lub powtarzają się regularnie, mogą już wpływać na widoczność strony w wynikach wyszukiwania. Google może ograniczyć częstotliwość indeksowania, a w skrajnych przypadkach nawet usunąć poszczególne podstrony z indeksu, uznając witrynę za niestabilną lub niskiej jakości. Dotyczy to szczególnie sytuacji, w których serwer zwraca błędy 5xx (np. 500, 503), oznaczające problemy techniczne po stronie hostingu.
Dodatkowo Mueller podkreśla, że odzyskanie utraconej pozycji w Google jest możliwe i zwykle zajmuje kilka tygodni — o ile problem z dostępnością został skutecznie rozwiązany. To podkreśla, jak ważne jest szybkie reagowanie na awarie oraz unikanie powtarzających się przestojów, które mogą prowadzić do długofalowych strat w widoczności strony i spadku ruchu organicznego.
Monitoring z różnych lokalizacji geograficznych
Jeśli Twoja strona kierowana jest do odbiorców spoza Polski — np. działasz na rynkach zagranicznych, prowadzisz sklep międzynarodowy albo oferujesz usługi w kilku językach — lokalny monitoring to za mało. Strona może działać perfekcyjnie w Polsce, a jednocześnie ładować się wolno lub być całkowicie niedostępna np. w Hiszpanii czy USA. Tego typu problemy mogą wynikać z awarii u regionalnych dostawców internetu czy z przeciążonej infrastruktury sieciowej na trasie przesyłu danych między użytkownikiem a serwerem.
Właśnie dlatego monitoring z wielu lokalizacji geograficznych pozwoli Ci wykryć problemy, których nie widać z poziomu kraju. Nowoczesne platformy testują strony z różnych kontynentów i dostarczają dane z perspektywy użytkowników w konkretnych regionach. To nie tylko pozwoli Ci szybko reagować na awarie, ale też poprawi jakość obsługi klienta w różnych częściach świata.
Jeśli natomiast Twoja działalność ogranicza się do Polski — wystarczy monitoring z jednej lub kilku krajowych lokalizacji.
Ochrona przed atakami DDoS i zagrożeniami bezpieczeństwa
Skuteczny system monitorowania uptime może również pełnić funkcję elementu zabezpieczeń, reagując na anomalie w ruchu sieciowym, podejrzane zachowania użytkowników czy atakami DDoS (rodzaj cyberataku polegający na przeciążeniu serwera poprzez wysyłanie ogromnej liczby zapytań jednocześnie).
Systemy monitorujące analizują zmiany w ruchu sieciowym i potrafią wykrywać nietypowe wzorce – jak nagły wzrost zapytań HTTP, dostęp z nieoczekiwanych lokalizacji czy gwałtowne spadki responsywności. Skuteczna analiza pozwoli Ci szybko rozpoznać próby ataku, awarie sprzętu lub błędy konfiguracji, zanim doprowadzą one do przestoju.
W reakcji na wykryte zagrożenie system może automatycznie zablokować ruch z określonych adresów IP, przekierować żądania do serwerów oczyszczających ruch z ataków DDoS lub uruchomić izolację zagrożonych węzłów sieci.
System powiadomień – jak otrzymywać powiadomienia w czasie rzeczywistym
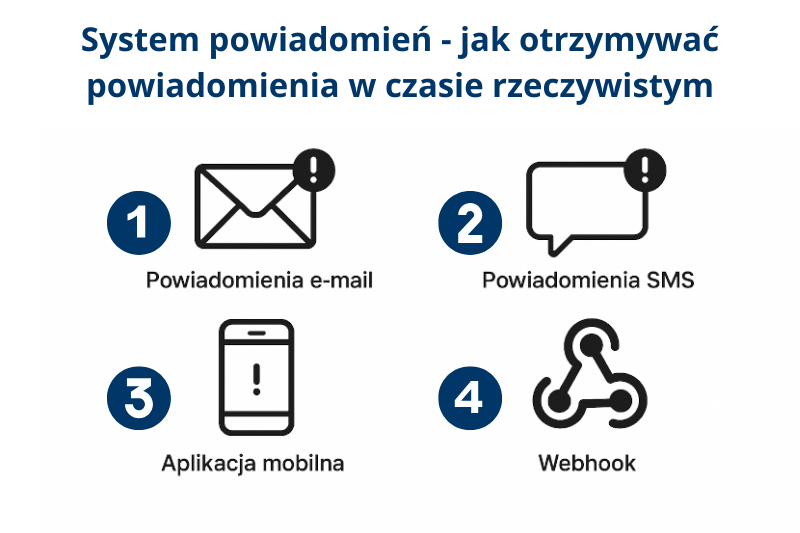
Skuteczny monitoring wymaga natychmiastowych powiadomień, które pozwolą Ci szybko zareagować na problemy. Nowoczesne narzędzia oferują zaawansowane systemy powiadamiania o trudnościach z dostępnością serwera. Możesz otrzymywać powiadomienia przez różne kanały:
- Powiadomienia e-mail – podstawowa i najczęściej używana forma kontaktu, idealna dla mniej krytycznych alertów. Wszystkie systemy monitoringu oferują tego typu powiadomienia.
- Powiadomienia SMS – dla krytycznych alertów wymagających natychmiastowej reakcji. Szczególnie przydatne, gdy nie masz stałego dostępu do poczty elektronicznej.
- Aplikacja mobilna – tzw. powiadomienia push, czyli krótkie komunikaty pojawiające się na telefonie bez konieczności otwierania aplikacji, dostępne są w mobilnych wersjach narzędzi monitorujących.
- Webhook – integracja z systemami firmowymi i automatyzacja procesów. Webhook to sposób na automatyczne przesyłanie informacji między różnymi aplikacjami internetowymi.
Szybka reakcja na problemy jest niezbędna dla minimalizowania wpływu przestojów na działalność firmy. Każda chwila niedostępności może bezpośrednio prowadzić do strat finansowych oraz osłabienia zaufania klientów.
Hierarchia alertów i automatyczne procedury
Skuteczny system powiadomień to nie tylko dobór właściwego kanału komunikacji, ale też czytelnie zdefiniowany przebieg eskalacji — kto i w jakiej kolejności powinien zostać poinformowany. Zwykle alert najpierw trafia do zespołu technicznego pierwszej linii. Jeśli problem nie zostanie rozwiązany w ciągu kilku minut (np. 5–10 minut w przypadku niedostępności strony), system automatycznie przekazuje powiadomienie do kolejnych osób – managerów IT, a w razie przedłużającej się awarii również do kadry zarządzającej.
Krytyczne incydenty, takie jak awaria strony głównej sklepu, powinny generować natychmiastowe powiadomienia SMS. Mniej istotne zdarzenia — np. pojedynczy błąd 404, krótkotrwałe spowolnienie panelu administracyjnego czy nieudana próba logowania — wystarczy sygnalizować mailowo. Dzięki temu nie rozproszy Cię nadmiar nieistotnych alertów, a jednocześnie zachowasz pełną kontrolę nad sytuacją.
Niektóre zaawansowane platformy oferują również automatyczne reakcje na określone problemy. Jeśli wykryją przeciążenie serwera, mogą samodzielnie uruchomić zapasowe instancje w chmurze, przekierować ruch do innego węzła lub aktywować procedurę failover — bez konieczności Twojej interwencji.
Monitoring sieci lokalnej i infrastruktury wewnętrznej

W przypadku firm posiadających własne serwerownie, biura z wieloma stanowiskami pracy lub rozbudowaną infrastrukturę IT, istotną rolę odgrywa także monitoring sieci lokalnej (LAN – sieci łączącej urządzenia w jednym miejscu).
Taki nadzór pozwala wykrywać problemy z działaniem serwerów wewnętrznych, połączeń między systemami czy urządzeń sieciowych – zanim wpłyną one na funkcjonowanie całej organizacji pod kątem wydajności. To kluczowe tam, gdzie istotna jest nie tylko dostępność usług dla klientów zewnętrznych, ale też sprawne działanie wewnętrznych narzędzi, takich jak systemy ERP, CRM czy firmowy intranet.
Analiza danych i raportowanie efektywności
Zebrane przez system monitoringu dane stanowią cenne źródło informacji do oceny efektywności infrastruktury IT oraz podejmowania strategicznych decyzji biznesowych. Do najważniejszych wskaźników należą: całkowity czas działania serwera (uptime), średnie czasy odpowiedzi, liczba i długość przestojów oraz dostępność poszczególnych usług.
Systemy monitorowania prowadzą szczegółową dokumentację wszystkich incydentów, co ułatwia analizę przyczyn awarii i planowanie usprawnień infrastruktury. Dane historyczne pozwalają na identyfikację powtarzających się problemów i wdrażanie działań zapobiegawczych.
Większość narzędzi oferuje wykresy, dashboardy i eksportowalne raporty. Te dane mogą posłużyć Ci do weryfikacji deklarowanego poziomu dostępności usług w zawartej z Tobą umowie SLA. Dzięki nim zyskujesz nie tylko pełną kontrolę nad działaniem infrastruktury, ale też możliwość ubiegania się o rekompensatę w przypadku niespełnienia warunków SLA przez dostawcę.
Gwarancje SLA i ich praktyczne znaczenie

SLA (Service Level Agreement) to umowa o gwarantowanym poziomie dostępności i jakości usług, zawierana między dostawcą a klientem. Stosuje się ją szeroko w różnych obszarach usług IT, takich jak:
- hosting (serwery współdzielone, VPS, dedykowane),
- utrzymanie i obsługa stron lub aplikacji,
- usługi SaaS (np. CRM, platformy e-commerce, systemy e-learningowe),
- dostawa łączy internetowych i usług CDN – np. Cloudflare,
- outsourcing IT,
- cyberbezpieczeństwo (np. ochrona DDoS, monitoring systemów),
- helpdesk i wsparcie techniczne.
W każdej z tych sytuacji SLA precyzuje, jakie parametry usług mają być utrzymane, np. dostępność, czas reakcji na zgłoszenie czy maksymalny czas usunięcia awarii.
Przykładowo, dla hostingu objętego SLA na poziomie 99,90% oznacza to maksymalny dopuszczalny czas niedostępności wynoszący około 44 minuty tygodniowo lub nieco ponad 72 minuty miesięcznie. Dla klienta jest to wyraźnie określony poziom gwarancji — jeśli dostawca hostingu nie wywiąże się z zadeklarowanych parametrów, zobowiązany jest do zapewnienia rekompensaty zgodnie z zapisami umowy SLA lub regulaminu usług.
Integracja z systemami firmowymi i automatyzacja procesów
Jeśli korzystasz z bardziej zaawansowanej infrastruktury, takiej jak serwery VPS czy dedykowane, możesz zintegrować system monitoringu z wewnętrznymi narzędziami używanymi w Twojej firmie. Dzięki API (interfejs programistyczny umożliwiający komunikację między aplikacjami) zautomatyzujesz kluczowe działania: tworzenie zgłoszeń w helpdesku, powiadamianie zespołu przez Slacka lub Teams, a nawet synchronizację statusów z systemami do zarządzania projektami.
Co najważniejsze — taka automatyzacja pozwala Ci utrzymać dostępność strony nawet w sytuacjach awaryjnych. Jeśli monitoring wykryje przeciążenie, system może samodzielnie uruchomić zapasową instancję aplikacji, skalować zasoby VPS-a lub przekierować ruch na inny serwer.
Możesz również powiązać dane techniczne z metrykami biznesowymi, np. spadkiem konwersji lub przychodów, co pozwoli Ci trafnie określić wpływ przestojów i mądrze zaplanować inwestycje w infrastrukturę.
W MSERWIS oferujemy elastyczne serwery VPS, które dają Ci pełną kontrolę i możliwość wdrażania zaawansowanych rozwiązań — takich jak automatyczne skalowanie zasobów, przełączanie instancji czy integracja z firmowymi systemami. To przewaga, której nie zapewni Ci standardowy hosting współdzielony — tam, nawet jeśli wykryjesz przeciążenie, nie możesz samodzielnie uruchomić żadnych działań naprawczych. Musisz czekać na interwencję wsparcia technicznego.
Planowanie przyszłości i optymalizacja kosztów

Skuteczna kontrola uptime to nie tylko bieżące wykrywanie awarii — to również cenne źródło danych wspierających strategiczne decyzje technologiczne. Analiza długoterminowych trendów w działaniu serwerów i aplikacji pozwoli Ci przewidywać momenty, w których konieczne będzie zwiększenie mocy obliczeniowej, rozbudowa infrastruktury lub modernizacja zasobów.
Zgromadzone dane techniczne — takie jak historia przestojów, czasy odpowiedzi czy stopień wykorzystania zasobów — są pomocne przy planowaniu budżetów IT oraz ocenie, kiedy warto zainwestować w nowe rozwiązania. Dzięki temu decyzje o wydatkach nie są oparte na intuicji, lecz na obiektywnych, mierzalnych wskaźnikach.
Monitoring uptime wspiera również ocenę efektywności dostawców usług IT — pokazuje, którzy partnerzy faktycznie zapewniają stabilność, a gdzie mogą występować chroniczne problemy. Warto więc korzystać z profesjonalnego systemu monitorowania, który nie tylko zapobiega przestojom, ale też długofalowo pomaga oszczędzać środki i rozwijać infrastrukturę we właściwym tempie.
Wybór odpowiedniego narzędzia – na co zwrócić uwagę

Nie każde narzędzie do monitoringu będzie odpowiednie dla każdej firmy. Małe strony mogą skorzystać z darmowych rozwiązań oferujących podstawowy nadzór, podczas gdy bardziej złożone środowiska mogą wymagać narzędzi z testami syntetycznymi, monitoringiem API czy analizą rzeczywistych użytkowników.
Przy wyborze platformy zwróć uwagę na:
- Możliwość integracji z używanymi systemami (np. Slack, Teams, webhooki).
- Dostępność polskiej wersji językowej i intuicyjnego interfejsu.
- Jakość i dostępność wsparcia technicznego.
- Częstotliwość testów i jasny podgląd ich przebiegu oraz wyników.
- Liczbę dostępnych lokalizacji testowych na całym świecie.
- Dostęp do bezpłatnego okresu próbnego w celu sprawdzenia pełnej funkcjonalności.
Darmowe narzędzia monitorujące uptime serwera
Na rynku dostępne są zarówno darmowe, jak i płatne rozwiązania do monitoringu dostępności. Darmowe sprawdzają się w prostych projektach. Oferują podstawową funkcjonalność, podczas gdy płatne plany zapewniają większą elastyczność, krótsze interwały testów, szerszy zasięg i zaawansowane opcje powiadomień. Do darmowych narzędzi należą na przykład:
- Site Quality Monitoring – to proste narzędzie dostępne w cPanelu (od wersji 110 wzwyż), o ile zostało aktywowane przez dostawcę hostingu. Monitoruje przede wszystkim dostępność strony internetowej z punktu widzenia użytkownika, czyli sprawdza, czy witryna odpowiada na zapytania z zewnętrznych lokalizacji. Pośrednio może to wskazywać na problemy z serwerem, choć równie dobrze niedostępność strony może wynikać z błędów aplikacji, przekroczenia limitów lub problemów z DNS. Narzędzie analizuje również szybkość ładowania, martwe linki, podstawowe błędy SEO, zgodność techniczną i bezpieczeństwo. W przypadku krytycznych problemów wysyłane są powiadomienia e‑mail.
- UptimeRobot – darmowy plan UptimeRobot umożliwia monitorowanie do 50 usług — w tym zapytań HTTP(S), pingów, portów oraz obecności określonych słów kluczowych na stronie. Testy wykonywane są co 5 minut, a użytkownik otrzymuje powiadomienia e-mail w przypadku wykrycia problemów. Dostępna jest integracja z narzędziami takimi jak Slack, Microsoft Teams czy Zapier. W wersji bezpłatnej monitorowanie realizowane jest z ograniczonej liczby lokalizacji.
- StatusCake – darmowy plan StatusCake pozwala na monitorowanie do 10 stron z interwałem co 5 minut. Oprócz podstawowej dostępności (uptime), obejmuje również jeden test prędkości strony, jeden monitor SSL oraz jeden monitor domeny. System wysyła powiadomienia e‑mail oraz obsługuje integracje z narzędziami takimi jak Slack, Discord i Microsoft Teams.
- HetrixTools – zapewnia monitorowanie do 15 usług (stron lub serwerów) z częstotliwością co minutę. Użytkownik może wybrać lokalizacje testowe spośród dostępnych czterech (dla planu free) lub nawet do 12 – zależnie od wersji konta. System oferuje powiadomienia e‑mail/webhook oraz zaawansowane funkcje diagnostyczne, takie jak zbieranie pingów i trasowania (MTR) w przypadku awarii, monitorowanie wygaśnięcia SSL, domen i nazw serwerów oraz przechowywanie nieograniczonej historii uptime. Plan darmowy wymaga jedynie aktywności – wystarczy zalogować się raz na 90 dni, by konto pozostało aktywne.
Płatne narzędzia monitorujące uptime serwera
Płatne rozwiązania oferują znacznie większe możliwości niż darmowe wersje – głównie przez krótsze interwały testowania, więcej lokalizacji, zaawansowane powiadomienia i szczegółowe raportowanie. Należą do nich:
- UptimeRobot – Plan Solo, dostępny w cenie ok. 7 dolarów miesięcznie, zapewnia testy co minutę, monitorowanie certyfikatów SSL i domen, tworzenie nieograniczonej liczby stron statusu, alerty SMS i webhook oraz rozbudowane opcje powiadomień (takie jak eskalacje i filtry). Dane historyczne przechowywane są przez okres jednego roku. Monitoring realizowany jest z wielu lokalizacji na całym świecie. Wyższe pakiety, takie jak Team i Enterprise, oferują możliwość nadzorowania większej liczby usług i skrócenia interwałów testowania.
- Uptrends – dostępne plany zaczynają się od około 16–17 dolarów/mies. (Starter/Business) do 54 dolarów/mies. (Enterprise). Zapewniają monitorowanie syntetyczne, transakcyjne, API (interfejsy programistyczne), SLA, Real User Monitoring (RUM), globalne testy z 230+ punktów, zrzuty ekranów błędów i integracje z narzędziami ITSM (IT Service Management).
- Pingdom (by SolarWinds) – podstawowa oferta zaczyna się od około 10–15 dolarów/mies. za pakiet z 10 testami uptime, 1 testem syntetycznym i 50 SMS-ami. To umożliwia sprawdzanie co minutę z globalnych lokalizacji, monitoring RUM, scenariusze syntetyczne, analizę czasu ładowania, status page i alerty e-mail, SMS, głosowe.
- Site24x7 – plan Pro kosztuje ok. 35 dolarów/mies. i obejmuje 40 monitorów, 1-minutowy interwał, 3 testy syntetyczne, Real User Monitoring (do 500 tys. odsłon), analizę sieci, status page (3x.), 150 SMS/połączeń miesięcznie i integracje biznesowe. Klasyczny plan to 89 dolarów/mies., Elite 225 dolarów, a Enterprise 449 dolarów miesięcznie.
Zaawansowane testy syntetyczne
Choć głównym celem monitorowania uptime jest wykrywanie awarii serwera, warto spojrzeć szerzej – bo dostępność strony to nie wszystko. Nawet jeśli serwer działa bez zarzutu, użytkownicy mogą napotkać błędy uniemożliwiające korzystanie z kluczowych funkcji. I właśnie tutaj wkraczają testy syntetyczne.
To osobna kategoria monitoringu, która nie dotyczy już samej dostępności usług, lecz poprawności działania aplikacji – np. formularzy, procesów logowania czy finalizacji zakupów. Ich zadaniem jest symulowanie prawdziwych interakcji użytkownika i wykrywanie błędów, które mogą nie wpływać na uptime, ale realnie obniżają konwersję czy powodują frustrację klientów.
Testy syntetyczne są dostępne w niektórych omawianych wcześniej płatnych platformach monitorujących, takich jak Pingdom czy Uptrends. Umożliwiają one np. symulowanie ścieżek użytkownika — logowania, dodawania produktów do koszyka, wypełniania formularzy czy finalizacji zakupu.
W praktyce warto łączyć klasyczny monitoring uptime z testami syntetycznymi – wtedy masz pełny obraz działania Twojej strony, zarówno od strony infrastruktury, jak i doświadczenia użytkownika.
Kiedy warto wdrożyć własny monitoring?

Własny monitoring należy wdrożyć zawsze wtedy, gdy to Ty zarządzasz serwerem i nikt inny nie zrobi tego za Ciebie. Dotyczy to przede wszystkim serwerów VPS i dedykowanych. W takiej sytuacji brak monitoringu oznacza brak reakcji na awarie – dopóki sam ich nie zauważysz.
Z kolei na hostingu współdzielonym to dostawca usług bierze na siebie odpowiedzialność za utrzymanie dostępności, monitoring infrastruktury i reagowanie na krytyczne problemy. W takich przypadkach wdrażanie własnych narzędzi nie jest konieczne – choć nawet wtedy warto rozważyć podstawowy, zewnętrzny monitoring jako dodatkowe źródło informacji o stanie strony.
Jeśli korzystasz z naszych usług hostingowych, nie musisz samodzielnie wdrażać zaawansowanych systemów monitorujących. To my odpowiadamy za dostępność Twojej strony – monitorujemy serwery z wielu lokalizacji, analizujemy wydajność i reagujemy natychmiast, gdy tylko pojawi się jakikolwiek problem. Dzięki temu nie musisz sprawdzać ręcznie, czy wszystko działa – masz pewność, że nad Twoją stroną zawsze ktoś czuwa.
Hosting ULTRA, BIZNES i serwery VPS – gwarantowany uptime serwerów ponad 99,95%
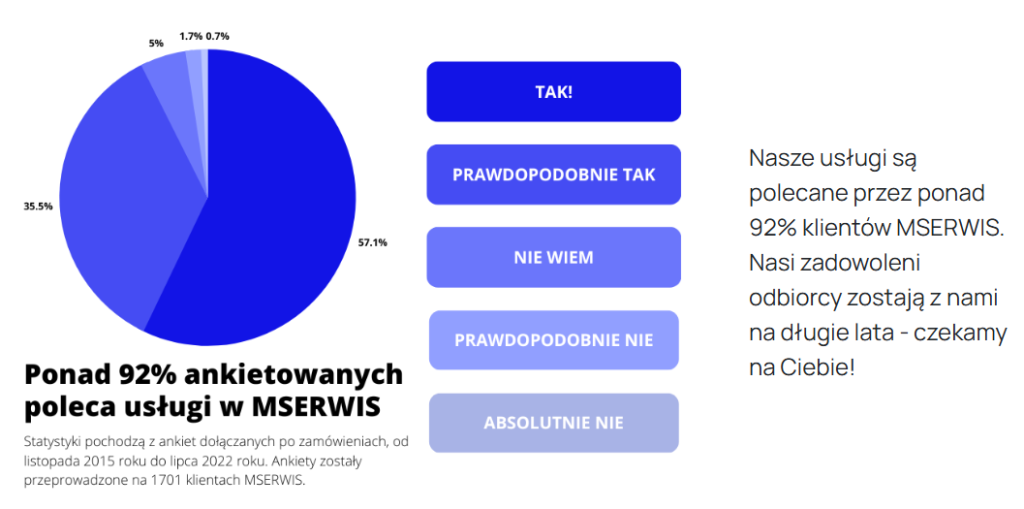
W ramach pakietów hostingowych ULTRA i BIZNES oraz serwerów VPS gwarantujemy dostępność usług na poziomie co najmniej 99,95%. Parametr ten objęty jest gwarancją SLA, a w przypadku jego przekroczenia klientowi przysługuje rekompensata zgodnie z regulaminem usługi.
Zapewniamy aktywne monitorowanie z różnych lokalizacji w Polsce i na świecie. Dzięki temu jesteśmy w stanie szybko wykrywać ewentualne problemy, niezależnie od miejsca, z którego użytkownik łączy się z serwerem. Całodobowy nadzór techniczny i automatyczne alerty pozwalają nam reagować proaktywnie – jeszcze zanim usterka wpłynie na dostępność strony lub usługi.
Pakiety ULTRA i BIZNES to także wsparcie techniczne oraz infrastruktura zoptymalizowana pod kątem stabilności i wydajności. W przypadku serwerów VPS zyskujesz dodatkowo pełną kontrolę nad środowiskiem – możesz wdrażać własne mechanizmy monitoringu, automatyzacji i skalowania, dostosowane dokładnie do potrzeb Twojego biznesu.


Podsumowanie – dlaczego warto zainwestować w monitoring
Kontrola uptime to strategiczna inwestycja w cyfrową przyszłość Twojej organizacji, która daleko wykracza poza proste sprawdzanie dostępności serwerów. Firmy, które priorytetowo traktują nadzór nad dostępnością swoich usług internetowych, zwiększają satysfakcję użytkowników, minimalizują ryzyko strat finansowych i budują większą odporność na zakłócenia biznesowe.
Współczesny biznes online opiera się na nieprzerwanej dostępności – dlatego monitoring uptime serwera to już nie opcja, lecz konieczność. Pamiętaj, że każda minuta przestoju może oznaczać nie tylko straty finansowe, ale również pogorszenie reputacji firmy i spadek zaufania klientów.
Własny monitoring serwera daje Ci natychmiastowy dostęp do informacji o dostępności usług — bez czekania na reakcję hostingu, automaty serwera czy zgłoszenia użytkowników. Nawet bezpłatne rozwiązania umożliwią Ci szybką interwencję, zanim problem zacznie eskalować.
Jeśli zależy Ci na najwyższej dostępności usług i profesjonalnym monitoringu bez kompromisów, poznaj nasze pakiety hostingowe ULTRA, BIZNES oraz serwery VPS. Gwarantujemy uptime na poziomie co najmniej 99,95% i całodobowy nadzór techniczny. Już teraz zapewnij sobie stabilność działania strony, szybkie wykrywanie awarii i nieprzerwaną dostępność usług.
Już od kilku lat zajmuję się planowaniem, koordynacją i realizacją działań marketingowych w MSERWIS.pl i Domeny.tv. Jestem odpowiedzialny za promowanie usług, produktów i oprogramowań mojej firmy. Aby jak najlepiej zrozumieć ich funkcje i zalety współpracuję z zespołem programistów i Biurem Obsługi Klienta. Wykorzystuję różnorodne taktyki i kanały marketingowe, żeby dotrzeć do potencjalnych klientów i przekonać ich do zakupu lub subskrypcji. Moje działania obejmują m.in. tworzenie kampanii marketingowych, pisanie materiałów marketingowych, zarządzanie mediami społecznościowymi oraz marketingiem e-mailowym i analizowanie rynku w celu zrozumienia potrzeb i preferencji docelowych odbiorców. Rozumiem technologię i potrafią przekazywać złożone koncepcje techniczne odbiorcom nietechnicznym. Mam doświadczenie w obszarach takich jak content marketing, SEO i generowaniu leadów. Potrafię skutecznie mierzyć i analizować wyniki działań marketingowych, aby stale ulepszać swoje strategie.

Polub nas na Facebooku



Komentarze